
AI is not just math and probabilities, just as the human brain is not just chemicals and electricity. While LLMs rely on mathematical operations, their ability to process and generate language is far more intricate than simple probability calculations.
Large Language Models (LLMs) like GPT-3 and ChatGPT have revolutionized artificial intelligence. They can generate human-like text, assist with complex tasks, and even simulate reasoning. But how do they actually work?
Many explanations of LLMs rely on advanced math: linear algebra, matrices, and deep learning equations. This can be intimidating. However, I want to offer a different approach: an intuitive, non-technical explanation inspired by 3Blue1Brown's incredible visual storytelling.
It is often said that LLMs do not "truly understand" language, that they simply predict text without reasoning. But this claim ignores the striking similarities between how LLMs process information and how human cognition functions. Both systems rely on pattern recognition, prediction, attention, and memory to interpret language. While human brains are vastly more complex, AI research is closing the gap by incorporating more components such as reasoning, vision, and planning.
This article aims to demystify how LLMs work, showing how their inner workings are closer to human cognition than many realize.
Step-by-Step: How LLMs Work in Simple Terms
1. Tokenization: Breaking Down Sentences
Before an LLM can process text, it first breaks it down into smaller units called tokens. Tokens can be:
Whole words (e.g., "apple", "orange")Subwords (e.g., "work" in "working")Individual characters (for languages like Chinese)
Imagine how humans learn to read: we break down sentences into words and phrases before understanding them. LLMs do the same through tokenization, converting text into numerical form for further processing.
For example, the sentence: "The cat sat on the mat." Might be tokenized as: [ "The", "cat", "sat", "on", "the", "mat", "." ]. Each of these tokens is assigned a unique numerical ID from the model's vocabulary, allowing it to be processed by neural networks.
However, tokenization isn't always simple:
Some tokenizers break words into subwords (e.g., "unbelievable" -> "un", "believ", "able").Spaces and punctuation matter (e.g., "New York" vs. "New" + "York").Some languages don't use spaces between words (e.g., Chinese, Japanese), requiring specialized tokenizers.
Tokenization allows LLMs to analyze text efficiently, ensuring that patterns across vast datasets are recognized at a fundamental level.
(For simplicity, in the following steps, I will assume that tokens correspond to whole words.)
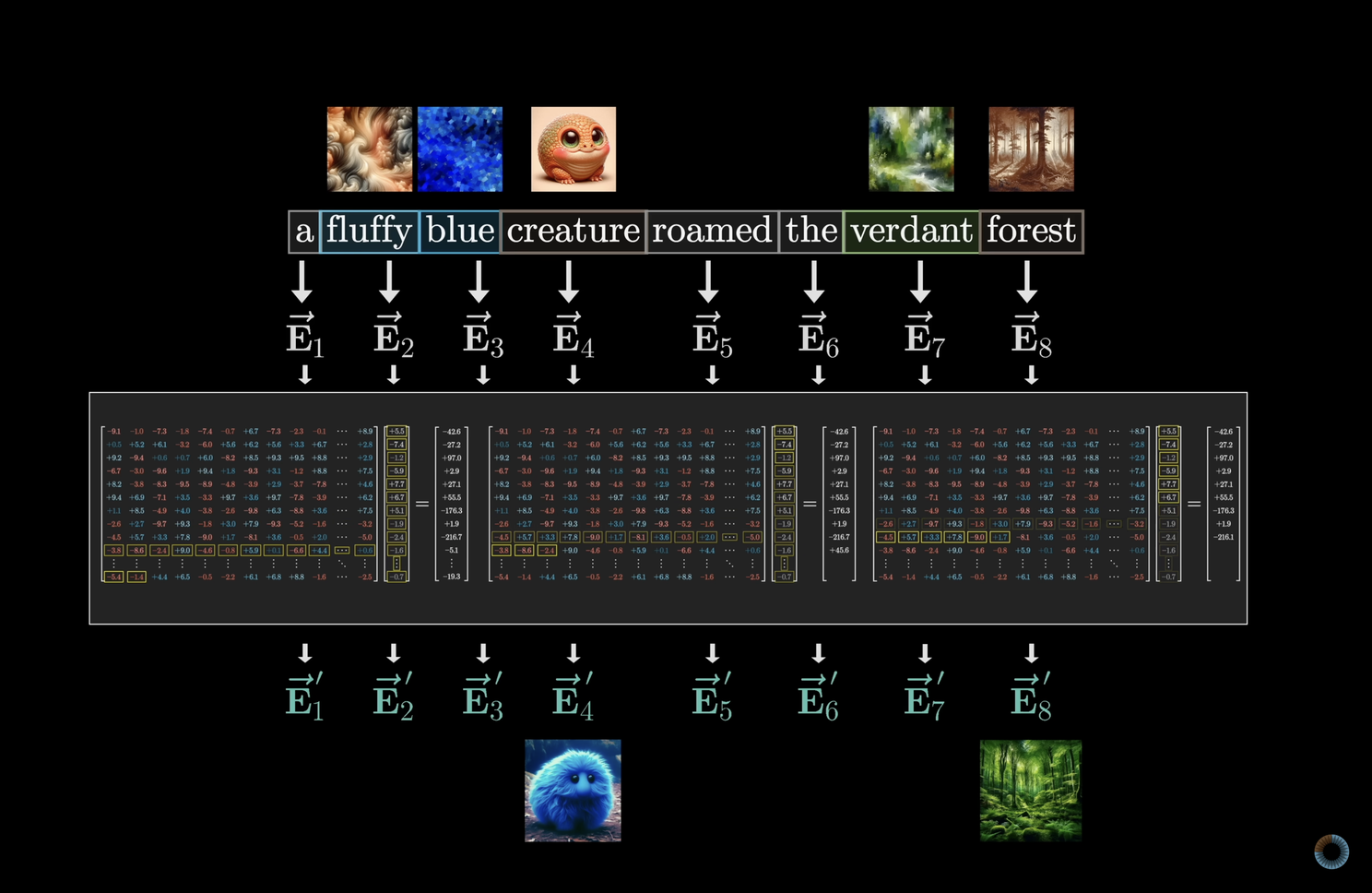
2. Embedding: Turning Words into Concepts
Once a sentence is tokenized, the model needs a way to understand the meaning of each token. However, computers don't process words, they work with numbers. This is where word embeddings come in.
Each token is converted into a high-dimensional vector representation: a list of numbers that capture the relationships between words based on their usage in language.
Words Exist in a Conceptual Space
Imagine that words exist in a multi-dimensional space, where their positions reflect their meanings and relationships.
For example:
"King" and "Queen" are positioned on a gender-related dimension."Dog" and "Cat" are positioned near each other in a pet-related dimension."Happy" and "Joyful" are grouped in a sentiment-related dimension.
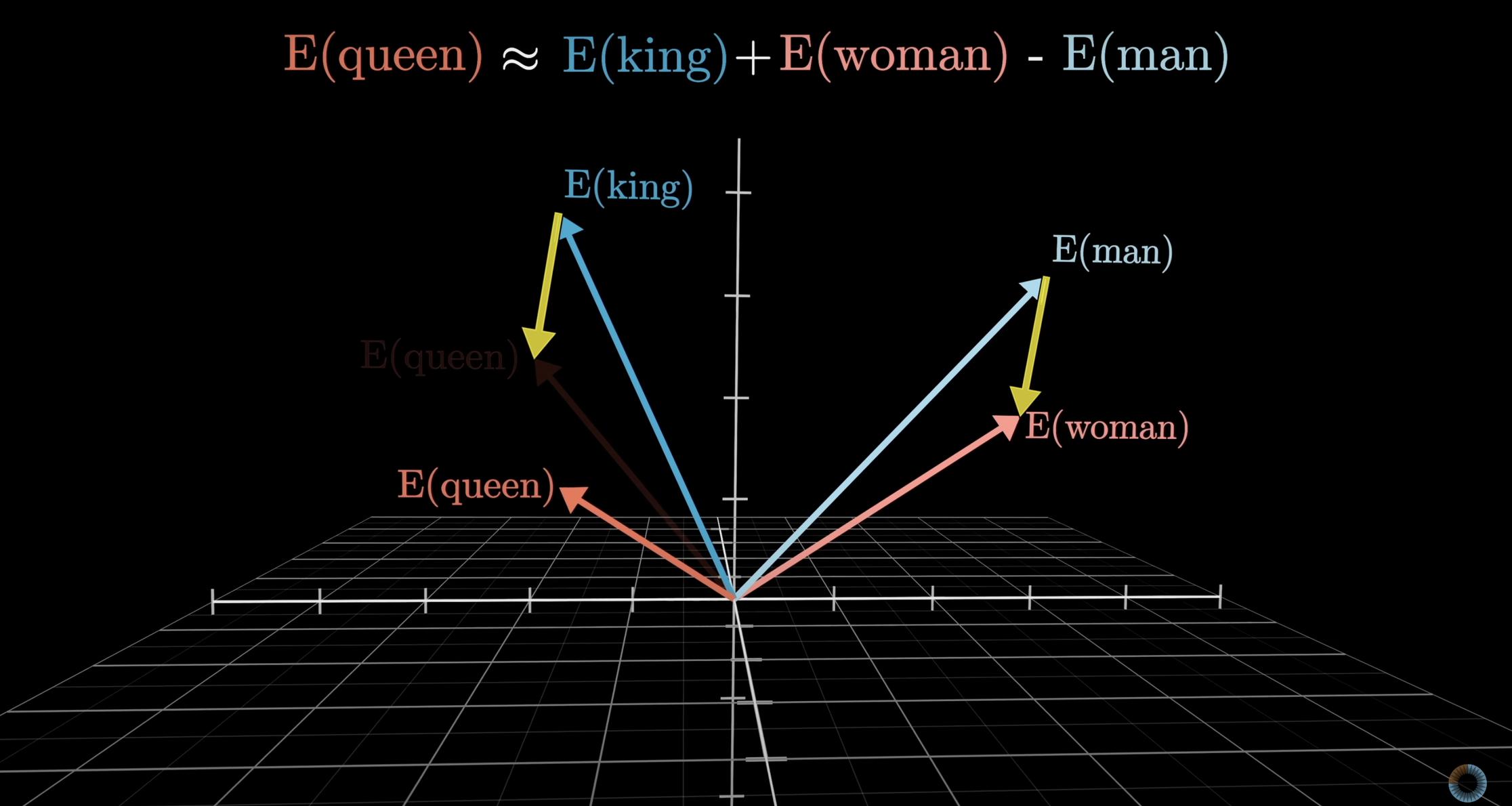
Although this is a classic example, Queen seems a bit far off. This can be explained by the fact that the embedding also holds other meanings for the word queen (the band, the LGBT slang, etc). The gender dimension is better illustrated by family relations:
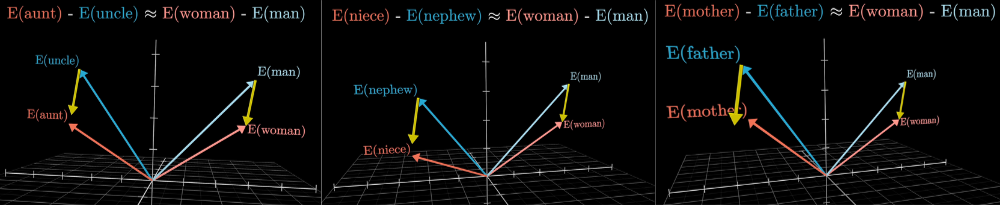
This allows the model to recognize synonyms, analogies, and relationships even if it has never explicitly been taught them.
Example analogy the model can infer from embeddings: "King" - "Man" + "Woman" = "Queen"
Each word embedding contains hundreds or thousands of dimensions, encoding attributes such as:
Plurality: ("dog" vs. "dogs")Verb tense: ("run" vs. "ran")Sentiment: ("happy" vs. "sad")Topics: ("finance" vs. "sports")
These concepts are not unique to AI. Neuroscientific studies suggest that the human brain also represents concepts in multi-dimensional spaces, forming clusters of related ideas based on experience.
Thus, embeddings allow LLMs to store and retrieve word meanings efficiently, acting as the model's conceptual knowledge base.
3. Attention: Focusing on What Matters
Understanding words individually is not enough: context matters. The same word can have different meanings depending on surrounding words. For example:
"He saw the bank from across the river." "She deposited money in the bank."
Here, "bank" refers to a riverbank in the first sentence and a financial institution in the second. How does the AI know which meaning to use?
This is where attention mechanisms come into play.
How Attention Works: The Query-Key-Value System
Each word in a sentence interacts with others through a query-key-value mechanism:
Query (Q): Each word asks, "Who is important to me?"Key (K): Each word stores information that might be useful to others.Value (V): The actual content of the words, weighted by importance.
Think of this like asking for advice in a meeting:
You (the query) ask a room full of experts which ones have relevant knowledge.Each expert (the keys) evaluates whether their expertise applies to your question.The most relevant experts provide their answers (the values) and contribute to your decision.
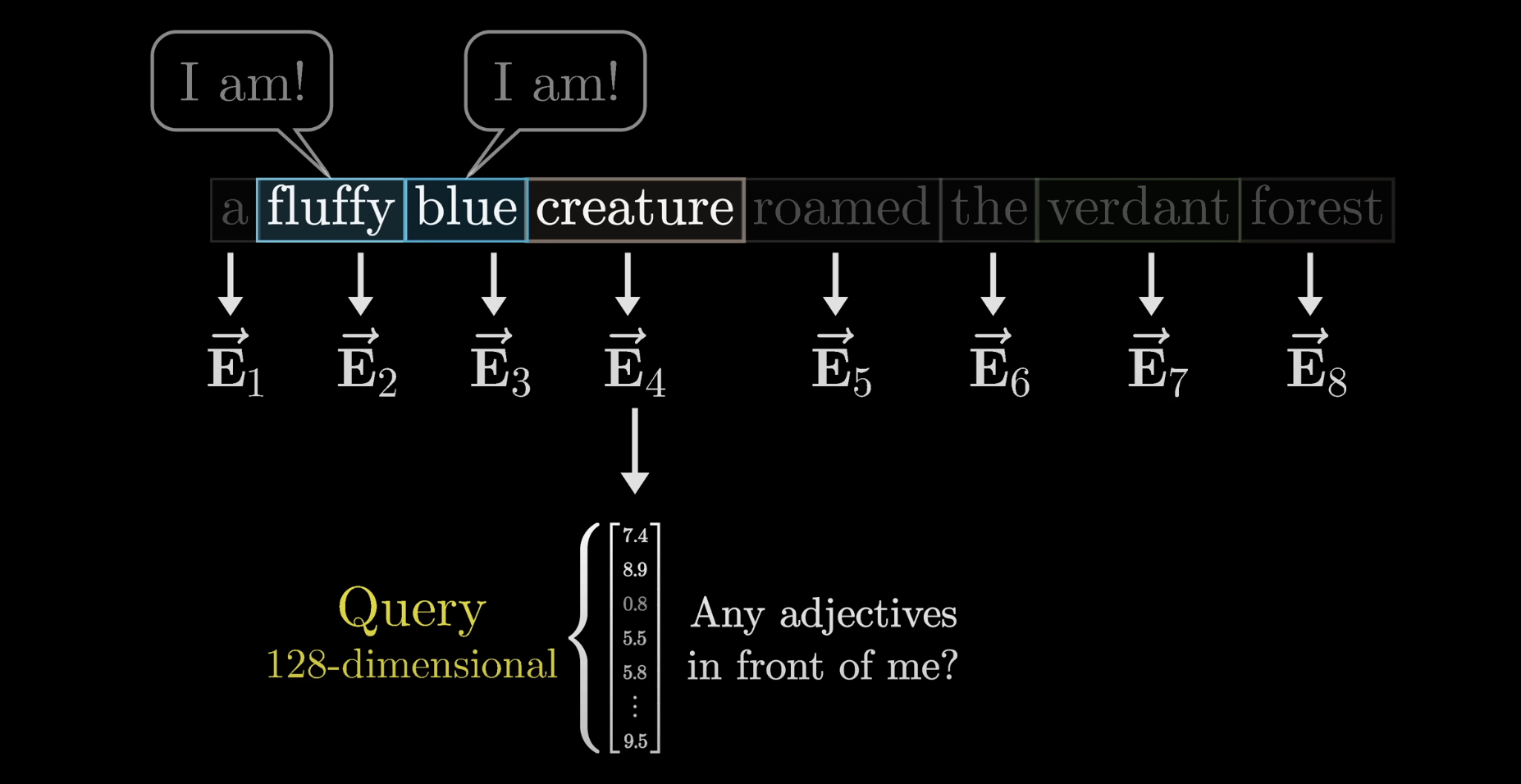
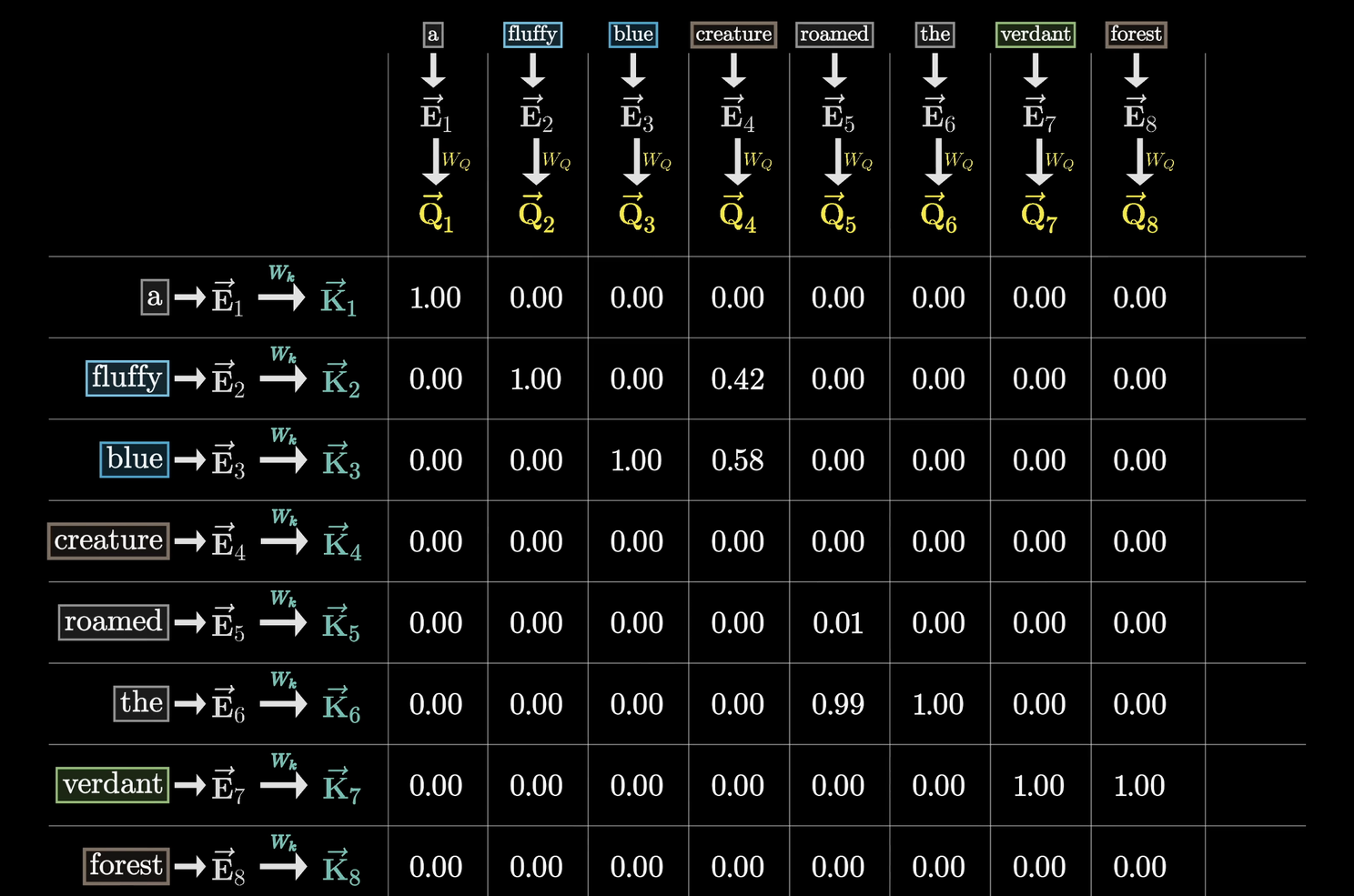
By asking the query (Q) questions for each word, and then identifying which other words are key (K) to answer the question, the model is able to update the value (V) of the word to reflect its new understanding:
For example, in the sentence:
"The cat sat on the mat because it was tired."
Query: "Because" asks, "What word explains the reason?"Key: "Tired" signals that it contains relevant information.Value: "Tired" contributes meaning to "because."
By computing attention scores, the model determines which words should influence each other the most.
Why Attention Matters
Attention enables LLMs to:
Resolve ambiguity (e.g., "bank" as a financial institution vs. a riverbank).Handle long-range dependencies (e.g., understanding a pronoun that refers to a subject mentioned earlier). Understand complex sentence structures (e.g., cause-and-effect relationships).Improve coherence by dynamically adjusting which words matter most at each layer.
Attention is recalculated multiple times across layers, refining how the model interprets words. This is why transformer-based LLMs (like GPT-3) can understand and generate coherent, context-aware responses.
4. Multi-Layer Perceptrons (MLPs): Refining Information and Testing Facts
After the attention mechanism determines which words are most relevant in a sentence, the model needs to process and refine this information. This is where Multi-Layer Perceptrons (MLPs) come in.
MLPs are small feed-forward neural networks that operate after attention layers, helping the model further interpret meaning and improve coherence before passing information to the next layer.
What Do MLPs Do?
MLPs act like post-processing layers, performing several key functions:
They refine attention outputs. While attention determines relevance, MLPs help interpret the meaning of words in context.They enhance complex relationships. MLPs allow the model to recognize subtle patterns, such as sarcasm, metaphors, or idioms.They reinforce factual consistency. If an earlier layer produces an incorrect fact, the MLP layers help suppress contradictions by referencing learned knowledge.They add non-linearity. Language relationships are complex, and MLPs introduce activation functions that allow the model to make more nuanced decisions instead of relying on simple linear transformations.
For example, consider the sentence:
"Paris is the capital of France."
The attention mechanism correctly identifies "Paris" and "capital" as strongly connected words.The MLP layers refine this connection, ensuring that "France" is the correct country and reinforcing that "Paris" is not the capital of Italy or Germany.

Why Are MLPs Important?
MLPs allow LLMs to move beyond simple word association and develop a more sophisticated understanding of language:
Improving logical flow: ensuring the generated text is not just statistically likely but also makes logical sense.Fact-checking within the model's knowledge: helping filter out contradictions and reinforcing consistency.Bridging gaps between concepts: connecting ideas that might not be directly related but share deeper associations.
MLPs work in tandem with attention layers, attention finds important connections, and MLPs refine and reinforce them, layer after layer.
5. Generating Responses: Iterating Through Layers
After the attention and MLP layers process the input, the model must predict the next word and construct a coherent response. However, this doesn't happen in a single pass. LLMs like GPT-3 use multiple stacked layers to refine their understanding.
For example, GPT-3 has 96 layers of alternating attention and MLP blocks, meaning that each input text is analyzed, refined, and re-evaluated 96 times before the model makes a prediction.
Why Do LLMs Use So Many Layers?
Each additional layer adds depth to the model's understanding, improving its ability to:
Ask more refined questions about the text. With every layer, the model queries previous layers to extract more meaning.Evaluate relationships between words more effectively. Early layers capture basic word relationships, while deeper layers understand long-term dependencies and abstract concepts.Extract and integrate more knowledge. Each layer allows the model to retrieve and combine relevant information from its stored knowledge.Improve factual consistency. If an early layer retrieves an incorrect fact, later layers have a chance to refine and correct it.
For example, when processing the sentence:
"The scientist who won the Nobel Prize for physics was born in 1921."
Early layers might detect individual words and their immediate relationships.Middle layers analyze sentence structure and check for contextual clues.Deeper layers assess whether the claim aligns with known facts (within the limits of its training).
Each pass through the layers reassesses and improves the model's understanding before making a final prediction.
How Does the Model Decide on the Next Word?
After processing input through multiple layers, the LLM assigns a probability distribution over possible next words.
For example, given the input:
"The sky is..."
The model calculates probabilities for possible continuations:
"blue" -> 85% probability"falling" -> 10% probability"delicious" -> 0.1% probability
The model samples from this distribution and picks the most likely word (or, in some cases, adds randomness to increase diversity).
This iterative process repeats for every new token until the response is fully generated.
This is what people often mean when they say LLMs are 'just probabilities'. But this unfortunate phrasing often gets transformed into 'AI does not understand but simply learns to guess', which does not account for how sophisticated this guessing is and that the AI learns to actually understand the concepts it processes and the questions it needs to ask.
However, there's a limit to adding layers. After a certain point, returns diminish, and computational cost increases. That's why researchers also focus on optimizing architecture instead of just increasing depth.
6. Training: How LLMs Learn Which Questions to Ask
Everything we've discussed so far (the ability to process tokens, apply attention, refine meaning through MLPs, and generate responses) doesn't happen magically. LLMs learn how to do this through training on massive datasets.
During training, the model is exposed to billions of sentences and gradually learns which questions to ask at each attention layer, how to evaluate relationships between words, and how to generate coherent text.
How Training Works: Learning from Data
LLMs are trained on massive datasets consisting of:
Books (literature, history, science, philosophy)Web articles (Wikipedia, news, research papers)Conversations (transcripts, dialogue datasets)Programming code (for code-based models)
The model does not memorize this data. Instead, it detects statistical patterns in language to learn how words relate to each other, how grammar functions, and what facts are commonly associated with certain phrases.
The key to this training process is next-word prediction.
Self-Supervised Learning: Predicting the Next Word
Instead of requiring humans to label data, LLMs train by simply predicting the next word in a sentence.
For example, if the training dataset contains:
"Paris is the capital of ___."
The model starts with random guesses. If it predicts "Germany," it receives a negative signal (error). If it predicts "France," it receives a positive signal (reward).
By repeating this process billions of times, the model adjusts its internal parameters to gradually improve its predictions.
How Training Teaches the Model to Ask Questions
Training is about learning which questions to ask at each layer:
Lower layers ask: Is this a noun or a verb? What is the grammatical structure?Middle layers ask: What entities are mentioned? Is this referring to a past event?Higher layers ask: What is the overall meaning? Is this text factual or opinion-based?
This is why deeper models perform better: with more layers, the model can refine its understanding, checking meaning at multiple levels before generating an output.
How the Model Improves Over Time
Training an LLM is an iterative process that occurs in multiple stages:
Pretraining: The model learns the general structure of language by predicting words in massive datasets.Fine-tuning: The model is refined for specific tasks, such as conversation, reasoning, or specialized knowledge.Reinforcement Learning from Human Feedback (RLHF): The model is further adjusted using feedback from human reviewers to improve its usefulness and safety.
Over time, this training enables LLMs to generate responses that aren't just grammatically correct but also contextually meaningful and factually grounded.
Why Training Never Truly Ends
Because LLMs are trained on fixed datasets, their knowledge is static. This is one of their main limitations when compared to the human brain. They cannot automatically learn new facts unless retrained. This is why AI research continues to explore ways to integrate live learning and real-time updates into language models.
Final Thoughts: The Future of AI and Human-Like Cognition
AI is often dismissed as just math and probabilities, but as we've seen, LLMs process language in ways strikingly similar to human cognition. While human brains rely on neurons, memory, and pattern recognition, LLMs operate through tokens, embeddings, attention, and multi-layered learning, mechanisms that mirror the way we store, retrieve, and process information.
The misconception that LLMs merely "predict the next word" fails to capture the depth of what's happening under the hood. Every word generated by an LLM results from:
Layers of learned associations built from billions of sentences.Context-awareness shaped by attention mechanisms.Iterative reasoning through multiple passes of evaluation.
With each technological advancement, the resemblance between AI and human cognition grows stronger.
Where AI Is Headed Next
The future of AI will be defined by our ability to integrate more components to create systems that more closely resemble human intelligence. Emerging research is focused on:
Multimodal AI: Integrating language, vision, and sound to understand the world holistically.Reasoning & Planning: Moving beyond text prediction to logical problem-solving.Memory & Adaptation: Allowing AI to retain and update knowledge dynamically, rather than relying solely on pre-trained datasets.Embodiment: AI systems connected to robotics that interact with the physical world.
As these components come together, AI will move from being a language simulator to a general problem-solving entity, further closing the gap between artificial and biological cognition.
AI Is Not Just Math
LLMs have already reshaped how we interact with technology. As they gain more capabilities, (vision, reasoning, memory, and adaptability) their functioning will increasingly resemble how humans process the world.
Rather than dismissing AI as just numbers and probabilities, we should recognize that it is becoming something far more sophisticated: a system that learns, refines, and adapts: just as we do.
Want to Go Deeper?
If you're not afraid of a bit more math and want to truly visualize how these models work, I highly recommend checking out 3Blue1Brown's video series on neural networks and deep learning or the courses available on their website. I have seen many attempts to demystify LLMs, and his videos are hand down the best. His videos provide a perfect balance of mathematical depth and intuition, making them a great next step for anyone curious about the inner workings of AI.


