
Ethical AI is a hot topic right now: spoken about in boardrooms, debated in parliaments, and discussed endlessly in media headlines. But let’s be honest: most of what’s being said is either too abstract to be useful or too dramatic to be realistic. There’s a lot of talk, but very little real understanding.
This isn’t about science fiction. It’s not about killer robots or an AI takeover. The real ethical implications of AI are already here and they’re shaping our everyday lives in subtle and not-so-subtle ways. From biased hiring algorithms to opaque credit scoring systems, from surveillance technologies to climate impact, AI is influencing how we live, work, and interact. And not always for the better.
Too often, ethical discussions are dominated by voices that don’t deeply understand how AI systems actually work. The people best positioned to explain both the benefits and the risks are those who understand the inner workings: the developers, researchers, and technologists building these systems. We have a responsibility not just to innovate, but to explain, challenge, and help shape how AI is governed and used.
This article is my attempt to break through the noise. To clarify what ethical AI really means, what principles should guide it, how things can go wrong, and what we can do about it. Not with fear, but with responsibility. Not with fantasy, but with grounded, technical, and human-centered reasoning.
1. What Is Ethical AI, Really?
When we talk about Ethical AI, we’re not talking about a single rulebook or a universal moral code baked into machines but about a commitment, a responsibility, to develop and deploy AI systems in ways that respect human rights, support social good, and minimize harm.
Ethical AI is about intentionally asking the right questions before problems arise, understanding who might be impacted, and building systems that reflect values like fairness, accountability, privacy, and transparency.
This shouldn't be a checklist you run through after the model is trained but a mindset that has to be embedded from day one: across the full lifecycle of an AI system: design, data collection, training, deployment, and monitoring.
It's also important to acknowledge that these principles don’t exist in isolation. Fairness can clash with accuracy. Transparency can clash with intellectual property. Privacy may come at the cost of performance. Navigating tradeoffs thoughtfully and evaluating each case on its own context should be at the core of any AI strategy.
Finally, ethics belongs to practitioners, not just regulators or philosophers. We need to move away from a passive view of AI governance and toward a world where the people building the systems are actively shaping their impact. That means asking: Who benefits from this model? Who might be harmed? How would this system behave in the real world outside the lab?
Understanding these questions is the foundation of ethical AI and the starting point for the principles we’ll explore next.
2. The Key Principles of Ethical AI
Before exploring the individual principles in detail, it’s important to recognize that ethical AI isn’t a new concept. Many organizations, governments, international bodies, and research institutions have already laid groundwork by proposing frameworks and tools to guide AI development responsibly. While the language varies, there’s a broad alignment around core values like fairness, accountability, transparency, and human well-being.
Notable Ethical AI Frameworks:
OECD AI Principles: A globally endorsed set of recommendations promoting responsible AI that is innovative, trustworthy, and centered around human values. AI Now Institute Policy Recommendations: A research-driven framework focused on holding AI systems accountable, especially those deployed in public service. UNESCO Recommendation on the Ethics of Artificial Intelligence: A comprehensive global framework advocating for inclusive, sustainable, and human-rights-based AI, particularly in low-resource and developing regions. EU Ethics Guidelines for Trustworthy AI: A European framework emphasizing the need for AI to uphold human dignity, individual rights, and democratic values, with a focus on transparency and fairness. IEEE’s Ethically Aligned Design Framework: A technical and philosophical guide that integrates ethical considerations like human agency, well-being, and societal benefit into the engineering process. Montreal Declaration for a Responsible Development of Artificial Intelligence: A citizen-centered initiative that outlines principles such as respect for autonomy, solidarity, and ecological sustainability to guide ethical AI. NIST AI Risk Management Framework: A U.S.-based approach that documents AI risks and provides practical tools and processes to help organizations identify, assess, and manage risks throughout the AI lifecycle.
3.1 Fairness and Non-Discrimination
Definition: Fairness in AI means ensuring that systems treat all individuals equitably, regardless of race, gender, age, socioeconomic status, or other protected characteristics. It is also about ensuring that AI does not replicate or amplify existing biases or discrimination.
In practice, this is one of the most urgent and difficult principles to uphold. AI models are only as fair as the data they're trained on. The issue is that data often reflects real-world inequalities. Moreover, fairness isn’t just technical definition but it’s social, legal, and contextual. What’s “fair” in one setting may be unjust in another.
🚫 Use Cases That Violate Fairness
- Facial Recognition Bias in Law Enforcement
Many facial recognition systems have shown significantly lower accuracy rates for people with darker skin tones. This has led to false arrests and surveillance that disproportionately targets minority communities.
Why it fails: The training datasets are often biased, underrepresenting certain demographic groups.
How to mitigate: Mandate demographic parity in training data, implement rigorous fairness audits, and, in some cases, restrict or ban the use of such systems in high-stakes contexts.
- Hiring Algorithms Favoring Majority Demographics
Some AI-powered recruitment tools have been found to favor male candidates or graduates from specific universities, simply because historical hiring data reflects those patterns.
Why it fails: The model learns from biased historical data and encodes those preferences as if they’re merit-based.
How to mitigate: Use debiasing techniques, audit for disparate impact, and involve human reviewers, especially in final hiring decisions.
- Credit Scoring Disparities
AI-driven credit scoring systems have shown tendencies to penalize individuals from low-income neighborhoods or certain ethnic groups, even when they have good credit behavior.
Why it fails: Proxy variables (like ZIP codes or spending patterns) can serve as stand-ins for race or class, embedding structural discrimination.
How to mitigate: Remove or carefully analyze proxy features, ensure explainability, and test models against fairness benchmarks across demographic slices.
✅ Positive Trend
A growing number of open-source libraries and toolkits such as IBM’s AI Fairness 360, Microsoft’s Fairlearn, and Google’s What-If Tool, are helping developers evaluate and address bias in machine learning models. These resources reflect a broader industry recognition that fairness needs to be measurable, testable, and built into the development process.
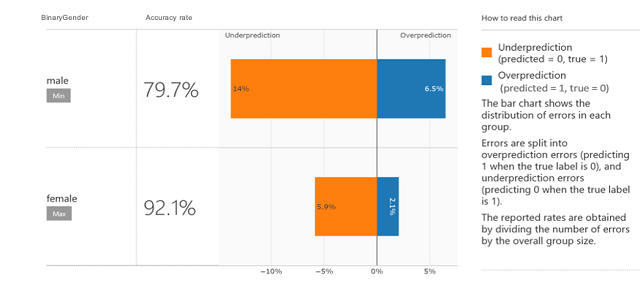
3.2 Transparency and Explainability
Definition: Transparency and explainability refer to the ability to understand how an AI system works, how it makes decisions, and what data and logic it relies on. Users, stakeholders, and regulators should be able to scrutinize AI systems, not just in theory, but in practice.
This principle is especially critical in high-stakes scenarios like healthcare, finance, or criminal justice, where decisions can have life-changing consequences. A model that works like a “black box” may be technically impressive, but if no one can explain its output, it becomes difficult to challenge or trust its decisions.
🚫 Use Cases That Violate Transparency and Explainability
- Medical Insurance Claims
Some AI models used in processing insurance claims do not offer any meaningful explanation to users who are denied procedures, which in some cases might be life saving. This has the added 'benefit' for the insurance company to hide behind the 'Black Box' excuse.
Why it fails: These systems often rely on complex algorithms that aren’t interpretable, making it impossible to justify or contest a decision.
How to mitigate: Use interpretable models when feasible, provide clear explanations to users, and implement regulatory requirements for model transparency.
- Predictive Policing Tools
AI systems that predict where crimes are likely to occur or who might reoffend are sometimes used without public insight into how predictions are made.
Why it fails: These systems are rarely open to audit, often rely on flawed or biased data, and may reinforce existing systemic issues.
How to mitigate: Require algorithmic transparency, enable third-party reviews, and engage affected communities in oversight.
- Healthcare Diagnostics Without Explanations
AI models used to detect diseases in radiology or pathology sometimes provide results without context or rationale to clinicians.
Why it fails: Clinicians cannot validate or challenge the model's output, which undermines medical judgment and patient safety.
How to mitigate: Design systems with explainable AI (XAI) components and integrate them into existing clinical decision-making processes.
✅ Positive Trend
Explainability is gaining traction not just in research but in tooling. Libraries like SHAP and LIME, along with explainability modules in platforms like TensorFlow and PyTorch, are making it easier to inspect model behavior. Regulators are also pushing for “right to explanation” laws, especially in sectors like finance and healthcare.
3.3 Privacy and Data Protection
Definition: Privacy and data protection involve safeguarding personal data from misuse, over-collection, and unauthorized access. AI systems should respect user privacy, adhere to data protection laws, and ensure that individuals retain control over how their data is collected, used, and shared.
AI often relies on massive datasets, many of which contain sensitive personal information. Without strong privacy safeguards, the risk of surveillance, data leaks, manipulation, or misuse becomes significant, especially as AI capabilities become more pervasive and predictive.
🚫 Use Cases That Violate Privacy and Data Protection
- Voice Assistants Recording Private Conversations
Several widely-used voice assistants have been found to activate and record audio without explicit user intent.
Why it fails: These devices sometimes listen beyond their intended use, storing sensitive information without clear consent.
How to mitigate: Implement strict on-device processing, improve voice activation accuracy, and ensure transparent data retention policies.
- Emotion Detection in Classrooms or Workplaces
Some AI systems are used to monitor facial expressions and voice tone to assess emotional states in schools or corporate environments.
Why it fails: These systems invade personal space, often without fully informed consent, and rely on questionable science.
How to mitigate: Ban high-risk emotion AI in sensitive contexts, enforce opt-in consent, and require rigorous validation of effectiveness.
- Behavioral Tracking in Apps and Platforms
AI-powered recommendation engines often collect granular behavioral data, from browsing habits to location, without meaningful user awareness or control.
Why it fails: Data is collected passively, and users are rarely given clear options to limit or understand what’s being tracked.
How to mitigate: Use privacy-by-design principles, provide granular privacy settings, and adopt stricter consent models.
✅ Positive Trend
The rise of privacy-preserving technologies, such as differential privacy, federated learning, and homomorphic encryption, is helping developers train AI systems without direct access to sensitive data. Additionally, regulations like the GDPR and CCPA have pushed organizations to take privacy more seriously, setting a global precedent.
3.4 Robustness and Safety
Definition: Robustness and safety refer to an AI system’s ability to function reliably under unexpected or adversarial conditions. It’s not enough for an AI to perform well in a controlled environment. It must also resist manipulation, degradation, or failure when exposed to real-world variability or malicious intent.
As AI systems are increasingly integrated into critical infrastructure and public-facing applications, ensuring they can’t be easily tricked or exploited becomes just as important as making them accurate.
🚫 Use Cases That Violate Robustness and Safety
- Adversarial Attacks on Autonomous Vehicles
Researchers have shown that something as simple as a specially designed T-shirt, sticker, or a few lines on a road sign can fool computer vision systems in self-driving cars, causing them to misclassify objects or miss obstacles.
Why it fails: AI models can be overly sensitive to visual noise or subtle perturbations in pixel data, even when humans would easily interpret the scene correctly.
How to mitigate: Train on adversarial examples, use sensor fusion (combining camera, LiDAR, radar), and implement multi-layered fail-safes.

- Prompt Injection in Chatbots and Language Models
Large language models can be manipulated via clever prompts, called “prompt injection”, to bypass safety measures and generate harmful, biased, or restricted content, or even leak private information.
Why it fails: The model lacks a true understanding of intent and can be tricked into treating malicious input as a valid instruction.
How to mitigate: Implement input sanitization, reinforce safety layers with supervised fine-tuning, and continuously update red-teaming strategies.
- Data Poisoning During Model Training
In open-source or federated learning scenarios, attackers can subtly insert malicious data into training sets, causing models to behave incorrectly on specific inputs, without affecting general performance.
Why it fails: Training pipelines may not verify data provenance or detect outliers, leaving the system vulnerable to long-term compromise.
How to mitigate: Use anomaly detection tools, establish data provenance protocols, and apply robust training techniques like differential privacy or adversarial training.
✅ Positive Trend
Security and robustness are becoming top priorities in AI development. A growing ecosystem of tools and research is helping identify and patch vulnerabilities before systems are deployed in the real world.
Techniques like adversarial training, input validation, anomaly detection, and reinforcement learning with human feedback (RLHF) are increasingly used to make models safer and more reliable. Tools like Safety Gym, red-teaming protocols, Robustness Gym, and open-source libraries like CleverHans and Foolbox allow developers to stress-test models against a wide range of threats.
Community-driven testing, formal verification, and independent audits are also playing a vital role, bringing more transparency and collective responsibility into the safety and robustness conversation.
3.5 Sustainability
Definition: Sustainability in AI refers to minimizing the environmental impact of developing, training, and deploying models. This includes energy consumption, hardware use, data center emissions, and the broader ecological footprint of AI infrastructure.
As AI models grow in size and complexity, their energy demands have skyrocketed, raising questions about their environmental cost, especially when they offer only marginal performance gains. Responsible AI must consider not just social harm, but ecological harm too.
🚫 Use Cases That Violate Sustainability
- Training Large Language Models Without Efficiency Considerations
Some state-of-the-art language models require millions of GPU-hours to train, emitting as much carbon as hundreds or thousands of transatlantic flights.
Why it fails: These models are often developed without transparency about their energy use, or any incentive to reduce it.
How to mitigate: Optimize architectures, use efficient hardware (like TPUs), and release energy benchmarks alongside model papers.
- Ignoring Energy Mix in Data Center Deployment
AI workloads are often run in regions with carbon-intensive energy grids, amplifying emissions, especially when operating 24/7.
Why it fails: Cloud computing locations are chosen for cost or latency, not environmental impact.
How to mitigate: Prioritize deployment in regions with cleaner energy (e.g., France, with its nuclear-heavy grid), and work with providers that use renewable power.
- Overuse of Inference at Scale
AI-powered features (like real-time translation, generative search, or recommendation engines) are sometimes deployed at massive scale even when benefits are marginal.
Why it fails: Inference costs are often overlooked, yet can eclipse training energy consumption over time.
How to mitigate: Apply cost-benefit analysis for deployment, use edge computing where appropriate, and encourage model reuse instead of redundancy.
✅ Positive Trend
Developers and researchers are becoming more aware of AI’s carbon footprint. Tools like CodeCarbon allow teams to track emissions during training and deployment, helping make sustainability a measurable goal. Frameworks like Green Algorithms, Carbontracker, and ML CO₂ Impact offer estimates of energy use and carbon emissions across different hardware and cloud setups.
There’s also growing interest in efficient model design (e.g., distillation, pruning, quantization) and carbon-aware scheduling, where workloads are run when electricity is cleanest, pushing sustainability from theory into real practice.
3.6 Inclusivity
Definition: Inclusivity in AI means ensuring that technologies are accessible, beneficial, and usable across different cultures, languages, abilities, and social contexts. It’s about designing systems that reflect and serve the full spectrum of human diversity, not just those who are already well-represented in data or development teams.
AI risks reinforcing existing global inequities if it is only optimized for high-resource languages, Western cultural assumptions, or tech-savvy users. Inclusive AI strives to avoid digital exclusion and actively seeks to bring underrepresented voices into the conversation.
🚫 Use Cases That Violate Inclusivity
- Language Models That Prioritize High-Resource Languages
Many AI models are heavily optimized for English and a handful of other widely spoken languages, while hundreds of languages are entirely unsupported or poorly served.
Why it fails: Lack of diverse training data and commercial incentives leads to exclusion of communities who can’t access or benefit from these technologies.
How to mitigate: Invest in multilingual datasets, partner with local linguistic communities, and build models that generalize across low-resource languages.
- Interfaces That Ignore Disability Access
AI-driven tools, from voice assistants to visual recognition, are often not designed with accessibility in mind, excluding users with vision, hearing, or mobility impairments.
Why it fails: Accessibility is rarely considered in the development process unless required by regulation.
How to mitigate: Follow inclusive design principles, involve users with disabilities in testing, and adopt accessibility standards like WCAG from the outset.
- Biased Content Moderation Systems
Automated moderation tools sometimes silence non-Western dialects, cultural expressions, or activist speech due to lack of contextual understanding.
Why it fails: Training data and moderation rules are often developed without cultural nuance or input from affected communities.
How to mitigate: Build localized moderation models, diversify content review teams, and allow community-led feedback mechanisms.
✅ Positive Trend
A notable effort in this space comes from Meta AI, where researchers, led in part by Yann LeCun, have developed No Language Left Behind, a multilingual translation model designed to support over 200 languages, many of which are considered low-resource. This kind of initiative actively pushes back against the English-first bias in AI and opens access to digital tools for millions of people who were previously underserved.
3.7 Accountability
Definition: Accountability in AI means that people, not just systems, must be responsible for the outcomes of AI decisions. When an AI system causes harm, makes a mistake, or produces biased results, there should be a clear line of responsibility: who built it, who deployed it, and who is answerable for its impact.
Without accountability, it becomes too easy to deflect blame onto “the algorithm” as if it were neutral or autonomous. Ethical AI requires transparency not only in design, but in ownership, oversight, and consequences.
🚫 Use Cases That Violate Accountability
- Denial of Responsibility in Algorithmic Hiring
When candidates are rejected by AI-based recruitment tools, companies sometimes claim they can’t explain or change the outcome because “the algorithm made the decision.”
Why it fails: This avoids responsibility and leaves individuals without a way to challenge or appeal decisions.
How to mitigate: Make AI a support tool, not the final decision-maker; require documentation of decision processes; and enforce appeals mechanisms.
- Public Sector Use of AI Without Oversight
Government agencies using predictive tools, for policing, benefits allocation, or fraud detection, can do so without transparency or public accountability.
Why it fails: These systems can affect vulnerable populations, but are rarely subjected to democratic scrutiny or clear performance evaluation.
How to mitigate: Mandate algorithmic impact assessments, publish model documentation, and create independent oversight bodies.
- AI-Generated Misinformation Without Source Tracing
As generative AI tools create fake news, impersonations, or misleading content, it becomes difficult to trace who used the tool, for what purpose, and with what intent.
Why it fails: There's no audit trail, making it hard to enforce ethical boundaries or legal responsibility.
How to mitigate: Implement watermarking or provenance tracking for generated content, and create accountability mechanisms for misuse.
✅ Positive Trend
There’s a growing push for model documentation standards, like Model Cards (by Google) and Datasheets for Datasets, that require developers to disclose how models are built, tested, and evaluated. In parallel, regulatory frameworks like the EU AI Act and proposed U.S. AI policy guidelines are beginning to define legal accountability for AI-related harm, especially in high-risk applications.
4. Governance Without Paralysis
If Ethical AI is to move beyond theory, it needs more than good intentions, it needs effective governance. But here’s the challenge: we must strike a balance. Governance should promote accountability, safety, and fairness, but without strangling innovation or slowing down progress to the point where others outpace us.
There’s a growing call for regulation, and rightly so. Clear rules are essential, especially for high-risk use cases like healthcare, law enforcement, and finance. But over-regulation or poorly designed compliance regimes can backfire, pushing innovation underground, consolidating power in a few large organizations, or locking out smaller players who can’t keep up with paperwork.
And there’s a geopolitical layer we can’t ignore. While some regions move toward strict governance (like the EU’s AI Act), others adopt a much more permissive approach. If only some countries follow ethical standards, we risk a race to the bottom, where ethical developers are punished for doing the right thing, while bad actors thrive in regulatory voids.
This is why ethical AI governance must be proactive, flexible, and globally aware. We can’t wait for perfect frameworks or international consensus. Those who understand how AI works need to become actors, not just commentators. That means:
Building systems with ethics embedded from the start, not as an afterthought. Supporting policy that’s informed by technical realities. Encouraging international cooperation while defending local values. Focusing on case-by-case evaluation, not rigid, one-size-fits-all rules.
Ultimately, AI governance must empower innovation that’s responsible, not paralyze it with fear.
5. Conclusion: Ethics in Practice
Blindly applying ethical guidelines, without understanding how AI actually works, can be just as harmful as ignoring them entirely. Well-intentioned rules can become counterproductive if they are overly abstract, poorly scoped, or disconnected from real-world systems.
In practice, the principles we’ve explored: fairness, transparency, privacy, robustness, sustainability, inclusivity, and accountability, often pull in different directions.
For example:
Maximizing transparency can expose sensitive personal data, challenging privacy. Prioritizing fairness might require sacrificing raw performance or scalability. Sustainability goals may conflict with robustness in large-scale deployments.
These tensions are not flaw, they’re the reality of building systems that interact with messy human and social environments. That’s why context matters. Every use case should be evaluated on its own terms, with input from those who understand both the technology and the people it impacts.
Ethical AI isn't something that can be fully automated, delegated, or outsourced. It must be built by people who are both technically literate and ethically grounded. Governance frameworks help, but they are only tools. What we need most are active, informed actors: developers, researchers, policymakers, and users who are ready to make difficult, thoughtful decisions in an evolving landscape.
The future of AI will not be defined by intentions alone, but by how we choose to act, case by case, system by system.


